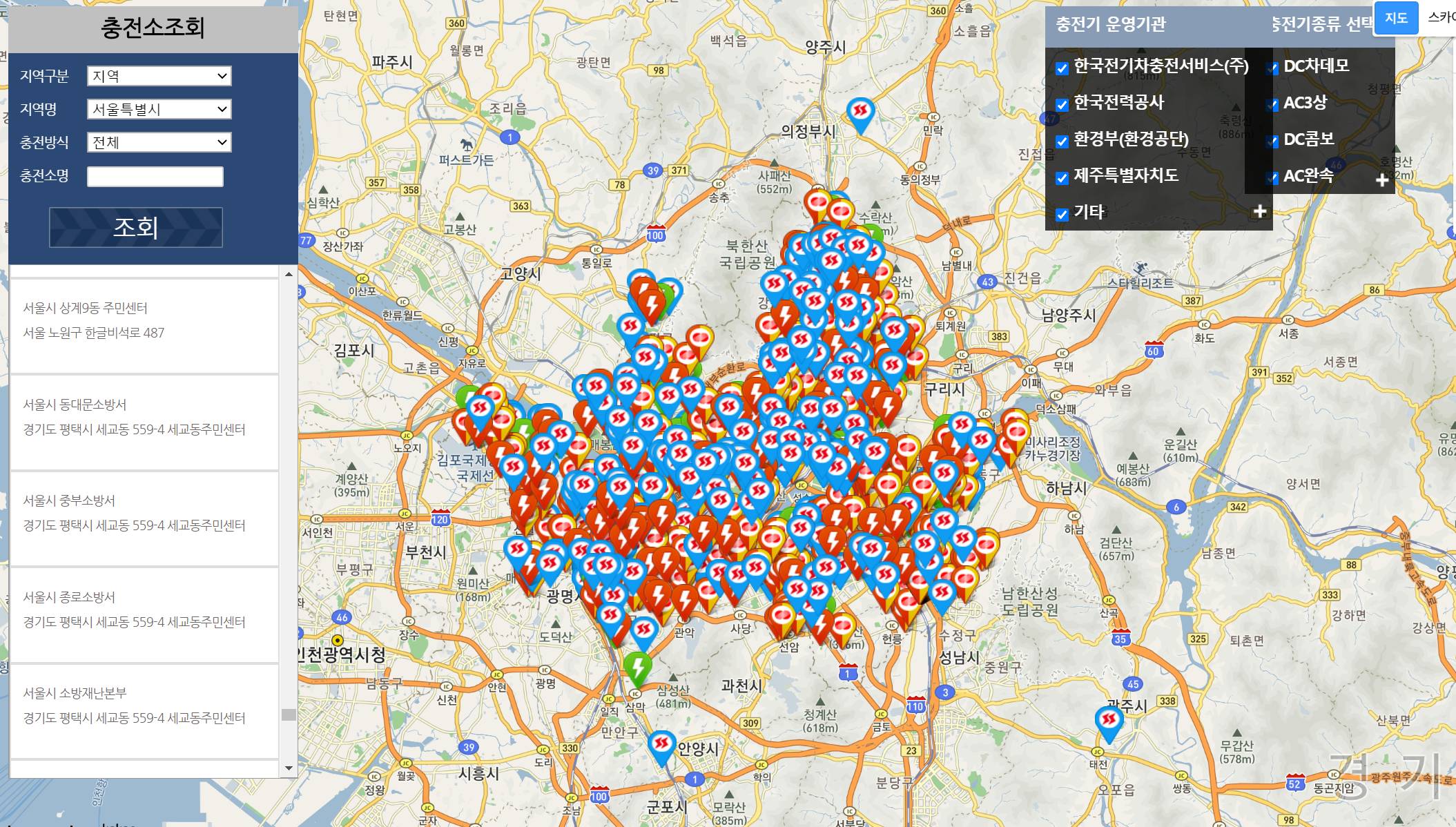
앞선 단계에서 데이터에 대한 수집과 간단한 처리 부분은 완료했다. 이제 이번 포스트에서는 본 프로젝트의 핵심인 H3의 사용의 시작과 쓰인 함수에 대한 소개를 하고자 한다.
H3는 Uber에서 개발한 육각형 그리드 시스템으로 파이썬으로 쉽게 그리드 시스템을 다룰 수 있다.
카일님의 블로그의 말을 빌리자면 육각형 그리드의 장점은 인접 타일 간의 거리가 같다는 점이 기존의 정사각형 그리드보다 강점을 지니며, 육각형 타일의 경우 재구성이 사각형 타일처럼 정확히 이루어지진 않으나, 약간의 회전과 함께 재구성이 가능하다.
(출처: https://zzsza.github.io/data/2019/03/31/uber-h3/)
서론은 줄이고 바로 H3 설치부터 다뤄보도록 한다.
0. H3 및 기타 패키지 설치
H3 패키지와 관련 함수들을 사용하기 위해 설치해야한 패키지의 목록은 다음과 같다.
- h3
- geopandas
- geojson
- simplejson
- branca (LinearColormap에 쓰임)
각 패키지가 pip를 통해 바로 설치가 되면 좋겠지만, geopandas의 경우 pip를 통해 설치를 하면 설치 오류가 발생했고 관련 문제가 자주 일어나는 듯 보였다.
이 곳(https://codedragon.tistory.com/9556)의 글을 따라서 pip 설치가 아닌 whl파일을 직접 내려받아 로컬에서 설치를 진행하는 방식으로 진행해야 하며, geopandas를 설치하기 앞서 설치해야하는 패키지가 몇개 존재한다...
1. pyproj
2. Shapely
3. GDAL
4. Fiona
5. geopandas
https://www.lfd.uci.edu/~gohlke/pythonlibs/
각각의 패키지에 대한 whl파일은 위의 링크에서 내려받을 수 있다. 각각의 운영체제와 python의 버전에 맞게 내려받는다.
(whl 파일을 통한 설치 방법)
명령 프롬프트에서 pip install ~~~.whl의 명령을 통해 설치 파일을 내려 받은 whl파일로 지정하여 설치를 진행한다. 나같은 비전공자의 경우 cmd에서의 디렉토리 변경이 익숙치 않아 번거로우므로 워킹 디렉토리에 파일을 옮긴 다음 바로 pip install을 진행하는것이 편할 것이다ㅎㅎ
[예시]
(User 폴더에 whl파일 이동) -> (명령 프롬프트 실행) -> pip install geopandas-0.7.0-py2.py3-none-any.whl
(설치를 마무리한 뒤에는 whl파일을 삭제해도 무관하다.)
from h3 import h3
import pandas as pd
from tqdm import tqdm_notebook
import folium
from folium import GeoJson
import branca.colormap as cm
from geojson import Feature, FeatureCollection
import simplejson as json본 단계에서 사용할 패키지들을 전부 import 했다.
위의 패키지를 전부 문제 없이 설치했다면 이렇게 라이브러리를 import해서 오류가 없는지 확인하고 다음 단계로 넘어가자.
1. H3 제공 주요 메서드
*프로젝트 중 설치한 패키지와 버전에 따라 메서드의 이름과 인자 이름이 다른 것을 확인하였으나, 공식 Documentation이 없어 이를 명확히할 수 없었다..!
아쉽게도 H3 패키지 자체에 시각화나 분석에 바로 쓸수 있는 메서드는 찾기 어렵다. h3패키지가 자체적으로 제공하는 주요 메서드들을 보면 다음과 같다.
1. geo_to_h3 : 위경도 좌표와 resolution을 받아 그 좌표가 속한 육각 타일의 id를 제공하는 메서드
2. h3_to_geo : 육각 타일 id를 받아 위경도 좌표 값으로 변환해주는 메서드
3. hex_ring : 육각 타일과 거리 k를 받아 거리가 k에 해당하는 타일의 id의 집합(set)을 반환하는 메서드
ex. k=2 -> 12개 타일 반환
4. k_ring : 육각 타일과 거리 k를 받아 거리가 k이하인 타일의 id의 집합(set)을 반환하는 메서드
ex. k=2 -> 1(거리=0) + 6(거리 =1) +12(거리=2) -> 총 19개 타일 반환
이런 주요 메서드를 보면 알 수 있듯이 h3 패키지가 분석을 자체적으로 도와주기보다는, 기존 geocode를 해당 위치와 resolution에 해당하는 타일 id를 반환해주고, 타일의 위치나 인접 타일에 대한 정보 정도를 다뤄주는 정도까지의 기능만 제공해준다,
즉 우리가 직접 육각 타일에 값을 부여하고, 그 결과를 시각화하는 작업은 직접 수행해야 된다는 것이다.
이를 위해 다음 단계에서 분석을 위한 함수를 직접 정의하는 과정을 다뤄보자!
2. H3 패키지 메서드 활용 함수
상술한 H3 패키지의 메서드를 이용해 분석단계에 활용한 함수들은 아래의 글에서 참고하였으며, 일부 수정을 거쳤다.
1. counts_by_hexagon
def counts_by_hexagon(df, resolution):
df = df[["lat","lng"]] # 데이터프레임에서 lat, lng만 가져와 처리
df["hex_id"] = df.apply(lambda row: h3.geo_to_h3(row["lat"], row["lng"], resolution), axis = 1)
# h3.geo_to_h3 메서드를 통해 위경도 좌표가 속한 그리드의 id를 입력받아 hex_id 칼럼에 저장
df_aggreg = df.groupby(by = "hex_id").size().reset_index() # hex_id를 기준으로 groupby하여, 행의 개수를 저장
df_aggreg.columns = ["hex_id", "value"] # 칼럼이름을 각각 hex_id와 value로 변경
df_aggreg["geometry"] = df_aggreg.hex_id.apply(lambda x: {"type" : "Polygon",
"coordinates":[h3.h3_to_geo_boundary(x,geo_json=True)]})
return df_aggreg가장 처음으로 활용하게 되는 함수이다.
우선 위도('lat')와 경도('lng')값을 갖고 있는 데이터프레임을 인자로 받아 위경도 좌표값이 위치하는 타일의 id를 변환하여 'hex_id' 칼럼에 저장한다.
그 다음 hex_id 칼럼으로 groupby하여 size메서드를 통해 각 hex_id의 카운트 값을 계산하여 'value'칼럼으로 저장한다.
또한 이 타일을 시각화하기 위하여 'geometry'칼럼을 만들어 그곳에 geojson형태의 자료형을 입력해주었다. type은 'Polygon', 좌표값은 h3의 h3_to_geo_boundary 메서드를 활용하여 해당 타일을 이루는 6개의 점의 좌표값 리스트를 사용하였다.
2. sum_by_hexagon
def sum_by_hexagon(df,column, resolution): #count_by_hexagon과 유사하나, 특정 칼럼값을 지정하여, 타일별 그 값의 합을 연산
df["hex_id"] = df.apply(lambda row: h3.geo_to_h3(row["lat"], row["lng"], resolution), axis = 1)
df_aggreg = df.groupby('hex_id')[column].sum().reset_index()# hex_id로 groupby한 뒤 지정한 칼럼의 sum을 계산
df_aggreg.columns = ['hex_id','value']
df_aggreg["geometry"] = df_aggreg.hex_id.apply(lambda x: {"type" : "Polygon",
"coordinates":[h3.h3_to_geo_boundary(x,geo_json=True)]})
return df_aggreg위의 count_by_hexagon을 응용한 함수로, 위경도 값이 있는 데이터프레임에서 특정 value가 담긴 값을 타일별로 총합하여 반환하는 함수이다. count_by_hexagon에서 groupby 집계 방식만 바꿔주었다.
3. mean_by_hexagon
def mean_by_hexagon(df,column, resolution): #sum_by_hexagon과 유사하나 총합이 아닌, 평균으로 집계함
df["hex_id"] = df.apply(lambda row: h3.geo_to_h3(row["lat"], row["lng"], resolution), axis = 1)
df_aggreg = df.groupby('hex_id')[column].mean().reset_index()#hex_id로 groupby하여 지정한 칼럼값의 평균으로 집계
df_aggreg.columns = ['hex_id','value']
df_aggreg["geometry"] = df_aggreg.hex_id.apply(lambda x: {"type" : "Polygon",
"coordinates":[h3.h3_to_geo_boundary(x,geo_json=True)]})
return df_aggregmean_by_hexagon은 마찬가지로 count_by_hexagon에서 groupby 집계 방식만 평균으로 바꾸어서 만들었다,
4. hexagons_dataframe_to_geojson
#hex_id와 value로 이루어진 데이터프레임을 geojson형태로 전환하는 함수
def hexagons_dataframe_to_geojson(df_hex, id='hex_id', value="value", file_output = None):
list_features = []
for i,row in df_hex.iterrows():
feature = geojson.Feature(geometry = row["geometry"] , id=row[id], properties = {"value" : row[value]})
list_features.append(feature)
feat_collection = geojson.FeatureCollection(list_features)
geojson_result = json.dumps(feat_collection)
#optionally write to file
if file_output is not None:
with open(file_output,"w") as f:
json.dump(feat_collection,f)
return geojson_result
5. choropleth_map
# hex_id별 value가 입력된 데이터 프레임을 코로플레스 시각화 지도로 바꾸어주는 함수
def choropleth_map(df_aggreg,geojson_data, value='val',location =[37.65,126.865] ,border_color = 'black', fill_opacity = 0.7, initial_map = None, with_legend = True, kind = "filled_nulls"):
#colormap시각화를 위한 중간값 m도출
min_value = df_aggreg[value].min()
max_value = df_aggreg[value].max()
m = round ((min_value + max_value ) / 2 , 0)
if initial_map is None:
initial_map = folium.Map(location= location, zoom_start=12)
# linear - 선형적인 관계를 나타냄 많고 적음을 나타내게 함
# outlier - outlier를 찾기 위한 choropleth -
# filled_nulls - linear와 같으나, 0인 값을 회색으로 칠함.
if kind == "linear":
custom_cm = cm.LinearColormap(['green','yellow','red'], vmin=min_value, vmax=max_value)
elif kind == "outlier":
custom_cm = cm.LinearColormap(['blue','white','red'], vmin=min_value, vmax=max_value)
elif kind == "filled_nulls":
custom_cm = cm.LinearColormap(['gray','green','yellow','red'],
index=[0,min_value,m,max_value],vmin=min_value,vmax=max_value)
geojson_data = geojson_data
folium.GeoJson(geojson_data,style_function=lambda feature: {
'fillColor': custom_cm(feature['properties']['value']),
'color': border_color,
'weight': 1,
'fillOpacity': fill_opacity}
).add_to(initial_map)
#add legend (not recommended if multiple layers)
if with_legend == True:
custom_cm.add_to(initial_map)
return initial_mapchropleth_map함수는 4번 hexagons_dataframe_to_geojson 함수로 만든 geojson 자료에 담긴 타일 정보를 folium 지도에 시각화하는 함수이다. 이름에 있는 것과 달리 본 함수는 folium의 Choropleth 메서드를 활용하는 것이 아닌, GeoJson 메서드를 활용하여 지도 위에 Polygon을 올린다. 인자로 받아주는 geojson_data에는 각 타일의 id와 그 위치가 담긴 'geometry'값이 있는데, 이를 참고하여 지도 위에 육각형 타일을 그리고, 각 타일에 대한 색깔은 branca의 LinearColormap 메서드를 활용하여 값의 크기에 비례하여 색을 결정한다.
이때, kind인자로 colormap으로 linear, outlier, filled_nulls 세 가지를 선택할 수 있다. linear은 기본적인 형태로 값이 작을수록 초록색, 클수록 빨간색을 띠는 colormap이며, outlier는 outlier가 아닌 일반적인 값은 흰색이고 값이 큰 부분과 작은 부분을 각각 빨간색과 파란색으로 채워준다. filled_nulls는 기본적으로 linear과 같은 colormap이나, 0인 부분을 회색으로 채워넣었다. (원래 코드에서는 다른 색이었는데 수정해 주었음.)
이외의 인자로는 Map의 시작위치를 설정하는 location, 타일들의 모서리의 색깔을 설정하는 border_color(없애고 싶은 경우 None), 타일의 불투명도를 설정하는 fill_opacity 등이 있다.
그 외에 인자로 설정할 수 있는 부분들이 함수에 존재하나, 본 프로젝트에서는 동일하게 사용될 인자는 따로 인자로 빼놓지 않았다.
6. get_neighbors, affect_neighbors
#hex_id값을 입력하면 인근 타일을 반환하는 코드. ring_size값에 따라 범위가 늘어남
def get_neighbors(h3_code,ring_size):
return list(h3.hex_ring(h3_code,k=ring_size))
#한 그리드의 value값을 인접타일에 특정 비율만큼 추가하는 함수
def affect_neighbors(df, ratio):
df = df.set_index('hex_id')
df_2= df.copy()
for h_id in tqdm(list(df.index)):
neighbor_list = get_neighbors(h_id,1)
for neighbor in neighbor_list:
if neighbor in list(df_2.index):
df_2.loc[neighbor,'value'] += df.loc[h_id,'value']*ratio
else:
df_2.loc[neighbor] = {'value':df.loc[h_id,'value']*ratio,'geometry':{"type" : "Polygon","coordinates":[h3.h3_to_geo_boundary(neighbor,geo_json=True)]}}
return df_2.reset_index()get_neighbors 함수는 하나의 타일 id에 대하여 인접한 타일의 id의 리스트를 반환하는 함수이다. ring_size를 인자로 설정하긴 했으나, 프로젝트 내에선 k=1로만 사용하였다.
affect_neighbors 함수는 타일 데이터가 담긴 데이터 프레임(df)과 비율(ratio)을 인자로 받아 각각의 타일에 대하여 인접한 타일에게 본 타일에 매핑된 값을 분배해주는 함수이다.
다음 포스트에서 위 함수들을 활용하여 앞서 수집한 데이터를 타일에 매핑하여 분석해 볼 것이다.
'Data Science > Projects' 카테고리의 다른 글
| 서울시 전기차 충전소 분석 프로젝트 2. 서울시 행정동별 생활인구와 위경도 좌표 변환 (0) | 2020.07.12 |
|---|---|
| 서울시 전기차 충전소 분석 프로젝트 1. selenium을 활용한 전기차 충전소 현황 데이터 수집 (2) | 2020.07.06 |
| 서울시 전기차 충전소 분석 프로젝트 0. 프로젝트 개요 (3) | 2020.07.06 |